



AI đang làm vấn đề đạo văn trở nên phức tạp hơn. Các nhà khoa học nên ứng phó như thế nào?
Việc áp dụng nhanh chóng các công cụ trí tuệ nhân tạo (AI) tạo ra văn bản đã đặt ra câu hỏi về việc liệu điều này có cấu thành đạo văn hay không và trong trường hợp nào thì được phép. Jonathan Bailey, một cố vấn về bản quyền và đạo văn có trụ sở tại New Orleans, Louisiana cho biết: " Việc sử dụng AI trải dài trên phạm vi rất rộng, từ hoàn toàn do con người viết cho đến do AI viết hoàn toàn — và ở giữa, có một vùng đất hoang vu rộng lớn của sự nhầm lẫn". Các công cụ AI tạo sinh như ChatGPT, dựa trên các thuật toán được gọi là mô hình ngôn ngữ lớn (LLM), có thể tiết kiệm thời gian, cải thiện độ rõ ràng và giảm rào cản ngôn ngữ. Nhiều nhà nghiên cứu hiện cho rằng chúng được phép trong một số trường hợp và việc sử dụng chúng phải được công khai đầy đủ. Nhưng những công cụ như vậy làm phức tạp thêm một cuộc tranh luận vốn đã căng thẳng xung quanh việc sử dụng không đúng cách tác phẩm của người khác. Các LLM được đào tạo để tạo ra văn bản bằng cách xử lý một lượng lớn các tác phẩm đã xuất bản trước đó. Do đó, việc sử dụng chúng có thể dẫn đến một điều gì đó tương tự như đạo văn — ví dụ như nếu một nhà nghiên cứu coi tác phẩm của một cỗ máy là của mình hoặc nếu một cỗ máy tạo ra văn bản rất giống với tác phẩm của một người mà không ghi rõ nguồn. Các công cụ này cũng có thể được sử dụng để ngụy trang văn bản cố tình đạo văn và bất kỳ việc sử dụng nào trong số chúng đều khó bị phát hiện. Pete Cotton, một nhà sinh thái học tại Đại học Plymouth, Vương quốc Anh, cho biết: " Việc xác định chính xác chúng ta thực sự có ý gì khi nói về gian lận học thuật hoặc đạo văn, cũng như ranh giới của chúng nằm ở đâu, sẽ rất, rất khó khăn. Trong một cuộc khảo sát năm 2023 với 1.600 nhà nghiên cứu, 68% số người được hỏi cho biết AI sẽ giúp phát hiện đạo văn dễ hơn và khó hơn. "Mọi người đều lo lắng về việc những người khác sử dụng các hệ thống này, và họ cũng lo lắng về việc bản thân mình không sử dụng chúng khi lẽ ra nên sử dụng", Debora Weber-Wulff, một chuyên gia về đạo văn tại Đại học Khoa học Ứng dụng Berlin cho biết. "Mọi người đều cảm thấy khá bối rối về điều này".
Đạo văn, theo Văn phòng Liêm chính nghiên cứu Hoa Kỳ định nghĩa là "việc chiếm đoạt ý tưởng, quy trình, kết quả hoặc từ ngữ của người khác mà không ghi rõ nguồn", là một vấn đề quen thuộc. Một nghiên cứu năm 2015 ước tính rằng 1,7% các nhà khoa học đã thừa nhận từng đạo văn và 30% biết những đồng nghiệp đã từng thực hiện hành vi này [1]. LLM có thể khiến mọi thứ tệ hơn. Đạo văn cố ý từ văn bản do con người viết có thể dễ dàng bị che giấu nếu ai đó yêu cầu LLM diễn giải lại từ ngữ trước. Muhammad Abdul-Mageed, một nhà khoa học máy tính và nhà ngôn ngữ học tại Đại học British Columbia ở Vancouver, Canada cho biết, các công cụ có thể được nhắc nhở để diễn giải lại theo những cách tinh vi, chẳng hạn như theo phong cách của một tạp chí học thuật. Một câu hỏi trung tâm là liệu việc sử dụng nội dung không ghi nguồn do máy móc viết hoàn toàn — thay vì do con người — có được coi là đạo văn hay không. Nhiều nhà nghiên cứu cho rằng không nhất thiết. Ví dụ, Mạng lưới toàn vẹn học thuật châu Âu, bao gồm các trường đại học và cá nhân, định nghĩa việc sử dụng các công cụ AI bị cấm hoặc không khai báo để viết là "tạo nội dung trái phép" thay vì được xem đạo văn như vậy [2]. Weber-Wulff cho biết: "Đối với tôi, đạo văn sẽ có những thứ có thể quy cho một người khác, có thể nhận dạng được". Bà nói thêm rằng mặc dù đã có những trường hợp AI tạo ra văn bản trông gần giống hệt với nội dung do con người viết hiện có, nhưng thường thì không đủ gần để bị coi là đạo văn. Tuy nhiên, một số người cho rằng các công cụ AI tạo ra đang vi phạm bản quyền. Cả đạo văn và vi phạm bản quyền đều là hành vi sử dụng không đúng tác phẩm của người khác và trong khi đạo văn là hành vi vi phạm đạo đức học thuật thì việc sử dụng trái phép tác phẩm có bản quyền có thể là hành vi vi phạm pháp luật. Rada Mihalcea, một nhà khoa học máy tính tại Đại học Michigan ở Ann Arbor cho biết: "Những hệ thống AI này được xây dựng dựa trên công trình của hàng triệu hoặc hàng trăm triệu người". Một số công ty truyền thông và tác giả đã phản đối những gì họ coi là vi phạm bản quyền của AI. Vào tháng 12 năm 2023, tờ New York Times đã đệ đơn kiện bản quyền chống lại gã khổng lồ công nghệ Microsoft và OpenAI, công ty Hoa Kỳ đứng sau LLM GPT-4, công ty cung cấp nền tảng chatbot ChatGPT. Vụ kiện tuyên bố rằng hai công ty đã sao chép và sử dụng hàng triệu bài viết của tờ báo để đào tạo LLM, những người hiện đang cạnh tranh với nội dung của ấn phẩm. Vụ kiện bao gồm các trường hợp mà lời nhắc khiến GPT-4 sao chép lại một số đoạn văn của bài báo gần như từng từ một. Vào tháng 2, OpenAI đã đệ đơn lên tòa án liên bang để bác bỏ một số phần của vụ kiện, lập luận rằng "ChatGPT hoàn toàn không thể thay thế cho một gói đăng ký (trả phí)" tờ The New York Times . Một phát ngôn viên của Microsoft cho biết "các công cụ do AI phát triển hợp pháp nên được phép phát triển một cách có trách nhiệm" và "chúng cũng không phải là sự thay thế cho vai trò quan trọng của các nhà báo". Nếu tòa án phán quyết rằng việc đào tạo AI về văn bản mà không được phép thực sự là vi phạm bản quyền, "đó sẽ là một sự thay đổi lớn đối với các công ty AI", Bailey nói. Nếu không có bộ đào tạo mở rộng, các công cụ như ChatGPT "không thể tồn tại", ông nói. Dù vậy, Hai phán quyết gần đây tại Mỹ, bao gồm vụ kiện liên quan đến Anthropic sử dụng hàng triệu cuốn sách để huấn luyện AI, cho thấy tòa án đang nghiên về quan điểm: Mọi nội dung công khai trên Internet đều có thể được sử dụng hợp pháp để huấn luyện AI theo nguyên tắc sử dụng hợp lý.
Cho dù có gọi là đạo văn hay không thì việc sử dụng AI trong bài viết học thuật đã bùng nổ kể từ khi ChatGPT được phát hành vào tháng 11 năm 2022. Các nhà nghiên cứu ước tính rằng ít nhất 10% tóm tắt trong các bài báo y sinh trong sáu tháng đầu năm 2024 đã sử dụng LLM để viết — tương đương với 150.000 bài báo mỗi năm. Các tác giả, do nhà khoa học dữ liệu Dmitry Kobak tại Đại học Tübingen ở Đức đứng đầu, đã phân tích 14 triệu bản tóm tắt trong cơ sở dữ liệu học thuật PubMed đã được xuất bản từ năm 2010 đến tháng 6 năm 2024. Họ chỉ ra rằng sự ra đời của LLM có liên quan đến việc sử dụng ngày càng nhiều các từ ngữ mang tính phong cách — chẳng hạn như 'delves', 'showcasing' và 'underscores' — và sau đó sử dụng các mẫu từ bất thường này để ước tính tỷ lệ tóm tắt đã được xử lý bằng AI (xem 'AI trong các bài báo học thuật'). Họ đã viết rằng "Sự xuất hiện của các trợ lý viết dựa trên LLM đã có tác động chưa từng có trong các tài liệu khoa học".
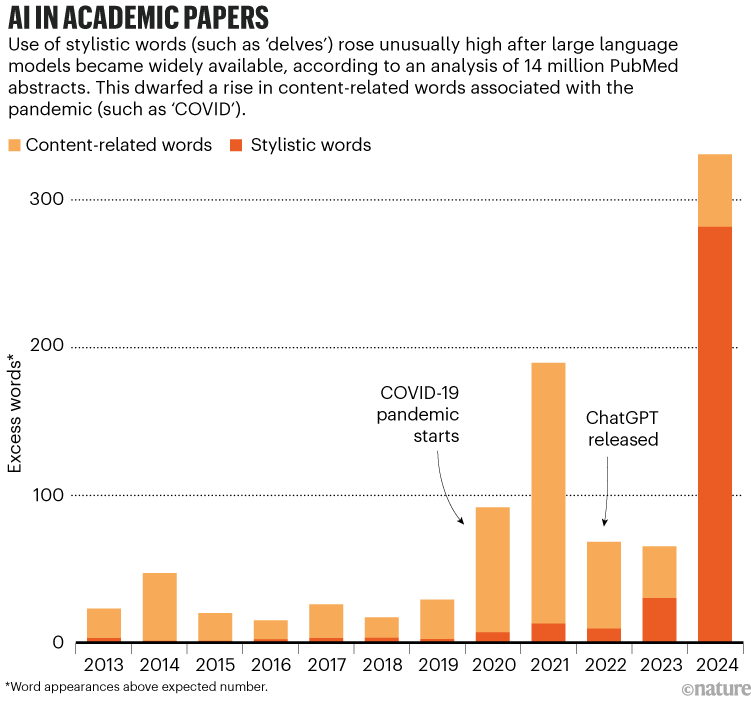
Nguồn: Kobak và cộng sự, 2024
Kobak và các đồng nghiệp của ông phát hiện ra rằng các bài báo từ các quốc gia bao gồm Trung Quốc và Hàn Quốc cho thấy dấu hiệu sử dụng LLM nhiều hơn so với các bài báo từ các quốc gia mà tiếng Anh là ngôn ngữ chính. Tuy nhiên, Kobak cho biết, các tác giả ở nhóm quốc gia sau này có thể sử dụng các công cụ này thường xuyên như vậy, nhưng theo những cách khó phát hiện hơn. Việc sử dụng LLM "chắc chắn sẽ tiếp tục tăng", Kobak dự đoán, và "có thể sẽ khó phát hiện hơn". Việc sử dụng phần mềm không được công bố trong bài viết học thuật không phải là điều mới mẻ. Từ năm 2015, Guillaume Cabanac, một nhà khoa học máy tính tại Đại học Toulouse, Pháp, và các đồng nghiệp của ông đã phát hiện ra các bài báo vô nghĩa được tạo ra bởi phần mềm có tên SCIgen và các bài báo có chứa 'cụm từ bị bóp méo ' được tạo ra bởi phần mềm tự động dịch hoặc diễn giải văn bản. Cabanac cho biết: "Ngay cả trước khi có AI tạo sinh, mọi người đã có các công cụ để ẩn mình". Và một số ứng dụng AI trong bài viết học thuật có giá trị. Các nhà nghiên cứu cho biết AI có thể làm cho văn bản và khái niệm rõ ràng hơn, giảm rào cản ngôn ngữ và giải phóng thời gian cho các thí nghiệm và suy nghĩ. Hend Al-Khalifa, một nhà nghiên cứu công nghệ thông tin tại Đại học King Saud ở Riyadh, cho biết trước khi các công cụ AI tạo ra khả năng này ra đời, nhiều đồng nghiệp của cô, những người coi tiếng Anh là ngôn ngữ thứ hai, sẽ gặp khó khăn khi viết bài báo. Cô cho biết "Bây giờ, họ đang tập trung vào nghiên cứu và loại bỏ sự phiền phức khi viết bằng các công cụ này". Soheil Feizi, một nhà khoa học máy tính tại Đại học Maryland, College Park, cho biết việc sử dụng LLM để diễn giải lại nội dung từ các bài báo hiện có rõ ràng là đạo văn. Nhưng việc sử dụng LLM để giúp diễn đạt ý tưởng — bằng cách tạo văn bản dựa trên lời nhắc chi tiết hoặc bằng cách chỉnh sửa bản nháp — không nên bị phạt nếu thực hiện một cách minh bạch. Feizi cho biết "Chúng ta nên cho phép mọi người tận dụng các mô hình ngôn ngữ lớn để có thể diễn đạt ý tưởng của mình một cách dễ dàng và rõ ràng hơn". Nhiều tạp chí hiện có chính sách cho phép sử dụng LLM ở một mức độ nào đó. Sau khi ban đầu cấm văn bản do ChatGPT tạo ra, Science đã cập nhật chính sách của mình vào tháng 11 năm 2023 để nói rằng việc sử dụng công nghệ AI trong khi viết bản thảo phải được công bố đầy đủ — bao gồm cả hệ thống và lời nhắc được sử dụng. Tác giả chịu trách nhiệm về tính chính xác và "đảm bảo không có đạo văn", tạp chí cho biết. Nature cũng cho biết tác giả của bản thảo nghiên cứu nên sử dụng phần phương pháp để ghi lại bất kỳ việc sử dụng LLM nào. (Nhóm tin tức và tính năng của Nature độc lập về mặt biên tập với nhóm tạp chí của mình.) Một phân tích về 100 nhà xuất bản học thuật lớn và 100 tạp chí được xếp hạng cao cho thấy đến tháng 10 năm 2023, 24% nhà xuất bản và 87% tạp chí đã có hướng dẫn về việc sử dụng AI tạo sinh [4]. Hầu như tất cả những người cung cấp hướng dẫn đều nói rằng một công cụ AI không thể được đưa vào làm tác giả, nhưng các chính sách khác nhau về các loại sử dụng AI được phép và mức độ công bố được yêu cầu. Weber-Wulff cho biết các hướng dẫn rõ ràng hơn về việc sử dụng AI trong bài viết học thuật là rất cần thiết. Theo Abdul- Mageed, hiện tại việc sử dụng tràn lan LLM để viết các bài báo khoa học đã bị hạn chế do những điểm yếu của chúng. Người dùng cần tạo các hướng dẫn chi tiết mô tả đối tượng, phong cách ngôn ngữ và lĩnh vực nghiên cứu cụ thể. Ông cho biết "Thực tế, việc để một mô hình ngôn ngữ tạo ra đúng chính xác những gì bạn muốn là rất khó". Nhưng các nhà phát triển đang xây dựng các ứng dụng giúp các nhà nghiên cứu dễ dàng tạo ra nội dung khoa học chuyên ngành hơn. Thay vì phải viết một lệnh chi tiết, trong tương lai, người dùng có thể chỉ cần chọn từ menu thả xuống các tùy chọn và nhấn nút để tạo toàn bộ bài báo từ đầu, ông cho biết.
Việc nhanh chóng áp dụng LLM để viết văn bản đã đi kèm với một loạt các công cụ nhằm mục đích phát hiện ra nó. Mặc dù nhiều công cụ tự hào có tỷ lệ chính xác cao — hơn 90%, trong một số trường hợp — nghiên cứu đã chỉ ra rằng hầu hết đều không đáp ứng được tuyên bố của họ. Trong một nghiên cứu được công bố vào tháng 12 năm ngoái [5], Weber-Wulff và các đồng nghiệp của cô đã đánh giá 14 công cụ phát hiện AI được sử dụng rộng rãi trong học viện. Chỉ có 5 công cụ xác định chính xác 70% hoặc nhiều hơn các văn bản là do AI hoặc con người viết và không có công cụ nào đạt điểm trên 80%. Độ chính xác của máy dò giảm xuống dưới 50%, trung bình, khi phát hiện văn bản do AI tạo ra mà ai đó đã chỉnh sửa nhẹ bằng cách thay thế các từ đồng nghĩa và sắp xếp lại các câu. Các tác giả đã viết rằng văn bản như vậy "gần như không thể phát hiện được bằng các công cụ hiện tại". Các nghiên cứu khác đã chỉ ra rằng khi yêu cầu AI diễn giải lại văn bản nhiều lần làm giảm đáng kể độ chính xác của công cụ kiểm tra [6]. Các công cụ dò AI còn gặp phải các vấn đề khác. Một nghiên cứu cho thấy chúng có xu hướng phân loại nhầm các bài viết tiếng Anh do AI tạo ra nếu tác giả không phải là người sử dụng tiếng Anh là ngôn ngữ gốc [7]. Feizi cho biết các máy dò không thể phân biệt đáng tin cậy giữa văn bản được viết hoàn toàn bằng AI và các trường hợp mà tác giả sử dụng các dịch vụ dựa trên AI để đánh bóng văn bản bằng cách hỗ trợ ngữ pháp và làm rõ câu. Ông nói rằng "Việc phân biệt giữa các trường hợp này sẽ khá khó khăn và không đáng tin cậy — và có thể dẫn đến tỷ lệ dương tính giả (nhận diện sai) rất lớn". Ông nói thêm rằng việc bị cáo buộc sai là đã sử dụng AI có thể "gây tổn hại khá lớn đến danh tiếng của những nhà khoa học hoặc sinh viên đó". Ranh giới giữa việc sử dụng AI hợp pháp và bất hợp pháp có khả năng sẽ mờ nhạt hơn nữa. Vào tháng 3 năm 2023, Microsoft đã bắt đầu tích hợp các công cụ AI tạo sinh vào các ứng dụng của mình, bao gồm Word, PowerPoint và Outlook. Một số phiên bản trợ lý AI của họ, được gọi là Copilot, có thể soạn thảo hoặc chỉnh sửa nội dung. Vào tháng 6, Google cũng bắt đầu tích hợp mô hình AI tạo ra của mình, là Gemini, vào các công cụ như Docs và Gmail. Debby Cotton, chuyên gia giáo dục đại học tại Đại học Plymouth Marjon, Vương quốc Anh, cho biết: "AI đang tích hợp vào hầu hết mọi thứ mà chúng ta sử dụng, tôi nghĩ rằng việc biết được liệu một sản phẩm nào đó có sự tham gia của AI không sẽ ngày càng trở nên khó khăn ", "Tôi nghĩ nó sẽ tiếp tục phát triển nhanh đến mức chúng ta khó có thể theo kịp".
By Diana Kwon. DOI: https://doi.org/10.1038/d41586-024-02371-z
Tài liệu tham khảo
[1] Pupovac, V., & Fanelli, D. (2015). Scientists admitting to plagiarism: a meta-analysis of surveys. Science and engineering ethics, 21, 1331-1352.
[2] Foltynek, T., Bjelobaba, S., Glendinning, I., Khan, Z. R., Santos, R., Pavletic, P., & Kravjar, J. (2023). ENAI Recommendations on the ethical use of Artificial Intelligence in Education. International Journal for Educational Integrity, 19(1), 1-4.
[3] Kobak, D., González-Márquez, R., Horvát, E.-Á. & Lause, J. Preprint at arXiv https://doi.org/10.48550/arXiv.2406.07016 (2024).
[4] Ganjavi, C., Eppler, M. B., Pekcan, A., Biedermann, B., Abreu, A., Collins, G. S., ... & Cacciamani, G. E. (2024). Publishers’ and journals’ instructions to authors on use of generative artificial intelligence in academic and scientific publishing: bibliometric analysis. bmj, 384.
[5] Weber-Wulff, D., Anohina-Naumeca, A., Bjelobaba, S., Foltýnek, T., Guerrero-Dib, J., Popoola, O., ... & Waddington, L. (2023). Testing of detection tools for AI-generated text. International Journal for Educational Integrity, 19(1), 1-39.
[6] Sadasivan, V. S., Kumar, A., Balasubramanian, S., Wang, W. & Feizi, S. Preprint at arXiv https://doi.org/10.48550/arXiv.2303.11156 (2023).
[7] Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7).
Phạm Lê Quốc Vinh - Khoa QTKD